
導語:作為2024年服貿會重要組成部分之一,國家衛生健康委員會百姓健康頻道(CHTV)定於9月13日在京舉辦“2024首都國際醫學大會的平行論壇——數智醫療與醫學人工智能創新論壇”,CHTV&醫學論壇網將為您帶來AI賦能醫療的係列報道,今天我們就來聊一聊大型語言模型的臨床應用現狀與不足。
01
醫療AI的現實挑戰:從潛力到實踐的無盡探索
在醫療領域,人工智能(AI)的引入被看作是提升醫療服務質量的關鍵。然而,盡管大型語言模型(LLM)在臨床實踐中的應用前景廣闊,它們在實際應用中的表現卻並非總能達到預期。2024年5月,斯坦福大學的Jenelle Jindal博士、Nigam Shah博士和同事們在一篇題為“Large Language Models in Healthcare: Are We There Yet? (醫療保健領域的大型語言模型:我們做到了嗎?)”的文章中深入探討了這一問題,指出了醫療AI在實現其臨床價值方麵存在的顯著差距,並提出了對現有研究方法的深刻反思。
盡管LLM在理論上具有巨大的潛力,但在實際應用中,它們在回答患者問題時可能會出現錯誤或幻覺。例如, LLMs在一項研究中回答患者問題時出現了明顯錯誤,這些錯誤在某些情況下甚至可能危及患者生命。這不僅暴露了醫療AI在安全性方麵的不足,也強調了對這些模型進行嚴格評估的必要性。目前的研究往往依賴於精心設計的數據集,而不是基於真實的患者護理數據,這限製了我們對LLM在實際醫療環境中表現的全麵理解。
此外,作者們強調了醫療AI與傳統AI在部署上的本質區別。傳統AI模型的更新迭代是有序的,而GenAI的快速發展和不斷湧現的新能力,打破了這一有序的更新模式。這種快速的技術進步,雖然帶來了新的可能性,但也帶來了評估和實施上的挑戰。為了實現GenAI在醫療領域的潛力,需要建立一套係統的評估框架。這一框架不僅需要涵蓋技術層麵的評估,還應包括對模型輸出的倫理、法律和社會影響的考量。作者認為,借鑒計算機科學領域對基礎模型的標準,可以為醫療AI的評估提供更為堅實的基礎。
02
精準評估,解鎖醫療AI潛力:精準導航臨床應用之路
作者指出,在醫療AI領域, LLM的臨床應用潛力正受到前所未有的關注。然而,現有研究多基於人工策劃的數據集,如醫學考試問題和案例摘要,而非真實患者護理數據。這種偏差限製了我們對LLM在實際醫療環境中性能的理解。例如,MedAlign研究中,醫生對LLM生成的響應進行了評估,這些響應針對的是特定電子健康記錄(EHR)中的臨床指令。盡管這一過程耗時且評估醫生間的一致性存在挑戰,但它凸顯了在真實患者數據上測試LLM的重要性。
在醫療任務的評估中,作者發現研究集中在特定領域,如通過美國醫學執照考試(USMLE)等醫學考試來增強醫學知識,而對診斷和治療建議的關注較少。這種集中趨勢可能導致對非臨床和行政任務的忽視,而這些任務在減輕醫生工作負擔方麵具有潛在的更大影響。例如,LLM在加快臨床試驗患者招募方麵的應用,可顯著提升招募速度並降低成本,這一點在社區醫院尤為關鍵,因為那裏的資源較少,難以有效篩選適合參與試驗的患者。
在評估維度的選擇和優先級方麵,作者指出除了準確性之外,還需要考慮公平性、偏見、有害性、穩定性以及部署時的考量等其他重要維度。LLM可能會在其輸出中反映訓練數據中的偏見,這在醫療領域尤其需要警惕。例如,一個LLM評估代理在評估1 300個響應時,展示了自動評估代理在檢測可能延續種族刻板印象內容方麵的潛力(表1、2)。這種評估工具的開發,如斯坦福大學的全麵語言模型評估(HELM),為標準化評估提供了新的方向,確保了在醫療領域中對所有重要評估維度的全麵考慮。
表1 評估維度定義精確度
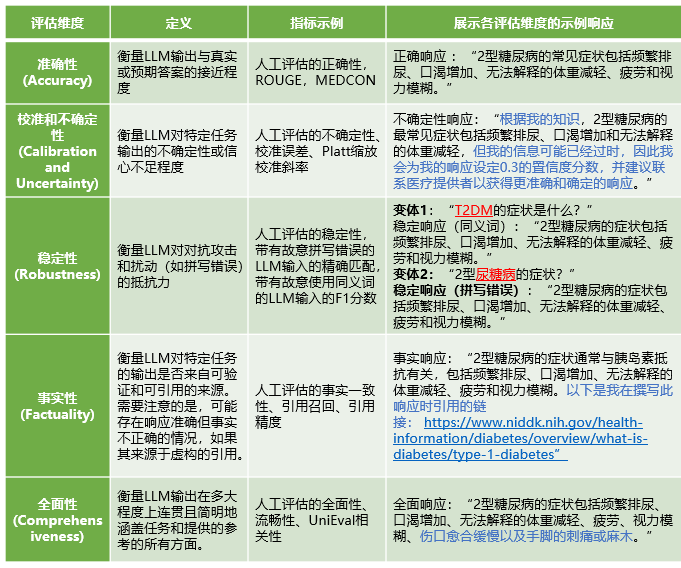
表2 其他評估維度
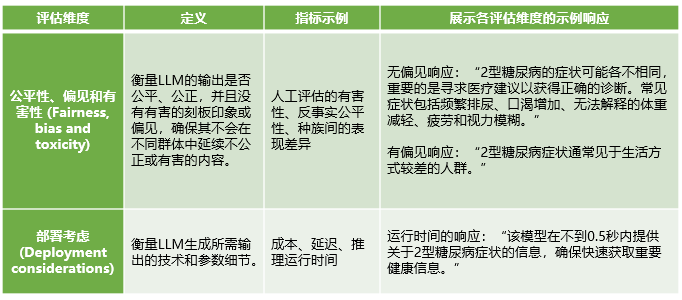
在亞專業測試方麵,作者指出,不同亞專業之間LLM評估的不平衡現象。核醫學、物理醫學和醫學遺傳學等專業在LLM相關任務的研究中尤為不足。這種不平衡可能會影響LLM在特定醫療領域的有效性和適用性。因此,作者呼籲對不同亞專業中的臨床任務進行全麵測試,以確保LLM能夠滿足不同醫療領域的特定需求。
03
總結
本文強調了對LLM進行係統性評估的重要性,以及在真實世界數據上測試的必要性。作者呼籲建立一個持續的評估循環,其中模型被構建、實施,然後通過用戶反饋不斷評估。這對於改善醫生的工作量和患者結果至關重要。通過這種方式,我們可以實現LLM在醫療領域的潛力,為臨床實踐帶來真正的變革。
參考文獻
JENELLE JINDAL , SUHANA BEDI, AKSHAY SWAMINATHAN, et al. Large Language Models in Healthcare: Are We There Yet?[Z/OL]. Stanford University Human-Centered Artificial Intelligence. [2024-5-8].https://hai.stanford.edu/news/large-language-models-healthcare-are-we-there-yet.
編輯:梨九
二審:且行
三審:清揚
排版:半夏
封麵圖源:醫學論壇網

